
본 포스팅은 Developing TaxGPT using OpenAI GPT and Chroma 게시물의 내용을 실습해본 것으로, 세법 관련 문제에 대한 답변을 얻을 수 있는 TaxGPT 어플리케이션을 만드는 것에 대한 내용입니다.이하 내용은 구글클라우드 환경에서 진행하였습니다. 먼저 실습을 위한 가상환경 생성에 앞서 conda 업데이트부터 진행한다..
==> WARNING: A newer version of conda exists. <==
current version: 4.9.2
latest version: 23.3.1
Please update conda by running
$ conda update -n base -c defaults conda실습용 가상환경을 생성하고 활성화시킨다.
(base) pluto@pluto:~$ conda create -n askGPT python=3
#
# To activate this environment, use
#
# $ conda activate askGPT
#
# To deactivate an active environment, use
#
# $ conda deactivate(base) pluto@pluto:~$ conda activate askGPT
(askGPT) pluto@pluto:~$
(askGPT) pluto@pluto:~$
(askGPT) pluto@pluto:~$ pwd
/home/pluto주피터노트북 구동하여 이후 실습을 진행한다. 주피터노트북 설치여부를 확인해보자.
(askGPT) pluto@pluto:~$ jupyter notebook --version
-bash: jupyter: command not found주피터노트북을 다음과 같이 설치한다.
(askGPT) pluto@pluto:~$ pip install jupyter
(askGPT) pluto@pluto:~$ which jupyter
/home/pluto/anaconda3/envs/askGPT/bin/jupyter
(askGPT) pluto@pluto:~$ jupyter notebook --version
6.5.4원격지에서 주피터노트북을 실행할 것이므로 아래 링크 참고하여 필요한 설정 후 실행한다.
2018.11.15 - [프로그래밍 Programming] - 브라우저에서 구글 클라우드 플랫폼 주피터 노트북 실행하기
하지만 다음과 같은 오류가 발생한다. 오래 전에 작성된 포스팅이다 보니 변경사항이 반영되지 않았다. 설정파일 내용 중 pylab 옵션을 주석으로 처리한 후 실행한다.
(askGPT) pluto@pluto:~$ jupyter notebook --ip=0.0.0.0 --no-browser --port=8888
[E 06:07:31.744 NotebookApp] Support for specifying --pylab on the command line has been removed.
[E 06:07:31.744 NotebookApp] Please use `%pylab inline` or `%matplotlib inline` in the notebook itself.
(askGPT) pluto@pluto:~$ jupyter notebook --ip=0.0.0.0 --no-browser --port=8888
[I 06:20:49.457 NotebookApp] Authentication of /metrics is OFF, since other authentication is disabled.
_ _ _ _
| | | |_ __ __| |__ _| |_ ___
| |_| | '_ \/ _` / _` | _/ -_)
\___/| .__/\__,_\__,_|\__\___|
|_|
Read the migration plan to Notebook 7 to learn about the new features and the actions to take if you are using extensions.
https://jupyter-notebook.readthedocs.io/en/latest/migrate_to_notebook7.html
Please note that updating to Notebook 7 might break some of your extensions.
[W 06:20:51.377 NotebookApp] All authentication is disabled. Anyone who can connect to this server will be able to run code.
[I 06:20:51.435 NotebookApp] Serving notebooks from local directory: /home/pluto
[I 06:20:51.436 NotebookApp] Jupyter Notebook 6.5.4 is running at:
[I 06:20:51.436 NotebookApp] http://pluto:8888/
[I 06:20:51.436 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
주소창에 다음과 같이 입력하면 정상적으로 작동함을 확인할 수 있다.
http://**.**.***.**:8888/tree?
작업할 폴더를 생성한 후 필요한 패키지 목록을 작성하여 설치한다.
%%writefile requirements.txt
openai
chromadb
tiktoken
langchain
%pip install -r requirements.txt
패키지 설치가 끝났다. 필요한 파이썬 패키지부터 가져와보자.
import os
import platform
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import time
import openai
import tiktoken
import langchain
import chromadb
chroma_client = chromadb.Client()
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import TokenTextSplitter
from langchain.llms import OpenAI
from langchain.document_loaders import UnstructuredURLLoader
import urllib
from urllib import request
print('Python: ', platform.python_version())Using embedded DuckDB without persistence: data will be transient
Python: 3.11.2Internal Revenue Codes 를 크롤링 및 스크랩한다.
def get_all_links(url, prefix):
try:
response = requests.get(url)
if response.status_code != 200:
print(f"Failed to load the page. Status code: {response.status_code}")
return []
soup = BeautifulSoup(response.text, "html.parser")
links = []
for link in soup.find_all("a"):
href = link.get("href")
if href:
absolute_url = urljoin(url, href)
if absolute_url.startswith(prefix):
links.append(absolute_url)
return links
except Exception as e:
print(f"Error: {e}")
return []
def crawl(url, prefix, depth, visited=None):
if visited is None:
visited = set()
if depth == 0:
return visited
links = get_all_links(url, prefix)
visited.add(url)
for link in links:
if link not in visited:
time.sleep(1) # Add a 3-second delay between requests
visited = crawl(link, prefix, depth - 1, visited)
return visitedurl = "https://irc.bloombergtax.com/" # Starting URL
url_prefix = "https://irc.bloombergtax.com/public/uscode/toc/irc/"
max_depth = 5 # Set the maximum depth of the crawl (0 for the starting URL only, 1 for its direct links, etc.)
visited_urls = crawl(url, url_prefix, max_depth)
print("List of URLs:")
for visited_url in visited_urls:
print(visited_url)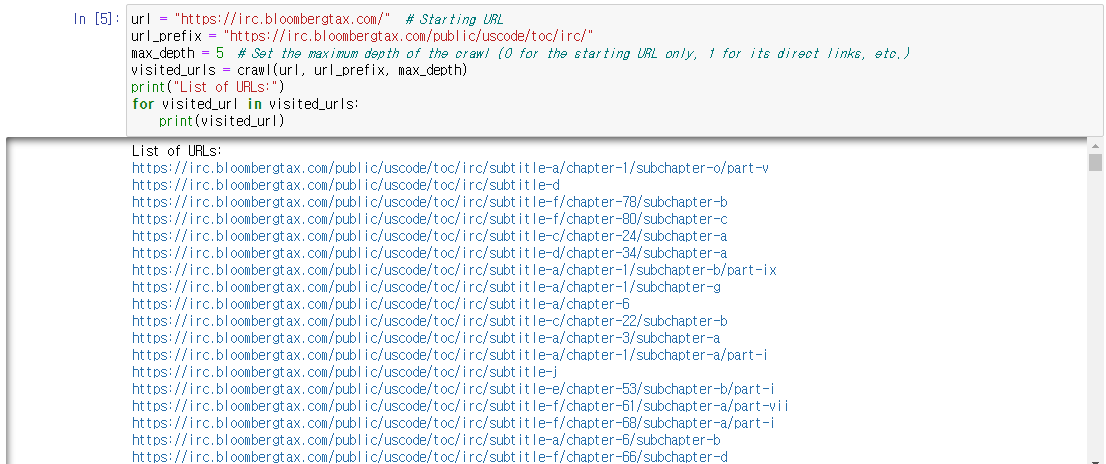
총 425개 URL 을 수집했다.
이제 다음으로 Internal Revenue Regulations 을 크롤링하자.
url_prefix = "https://www.irs.gov/irb/"
max_depth = 2 # Set the maximum depth of the crawl (0 for the starting URL only, 1 for its direct links, etc.)
visited_urls = set()
for page_number in range(21):
url = f"https://www.irs.gov/irb?page={page_number}" # Starting URL with page number
visited_urls = visited_urls.union(crawl(url, url_prefix, max_depth))
print("List of URLs:")
for visited_url in visited_urls:
print(visited_url)실행에 너무 오랜 시간이 걸린다. 얼마나 진행되었는지 알 수가 없다.
max_depth = 1 로 수정하고 진행상태를 알기위해 다음과 같이 코드를 수정했다.
from tqdm import trange, notebook
url_prefix = "https://www.irs.gov/irb/"
max_depth = 1 # Set the maximum depth of the crawl (0 for the starting URL only, 1 for its direct links, etc.)
visited_urls = set()
for page_number in notebook.tqdm(range(21)):
url = f"https://www.irs.gov/irb?page={page_number}" # Starting URL with page number
visited_urls = visited_urls.union(crawl(url, url_prefix, max_depth))
print("List of URLs:")
for visited_url in visited_urls:
print(visited_url)
이제 환경설정을 진행할 차례다. 스토리지를 마운트하는 내용이 나오는데, 구글 클라우드에서 진행하므로 아래 내용은 필요없다.
from google.colab import drive
drive.mount('/content/drive')OpenAI API 키를 입력한다.
os.environ["OPENAI_API_KEY"] = "openai api key"
openai.api_key = os.getenv("OPENAI_API_KEY")Internal Revenue Codes 임베딩 데이터베이스를 만들 차례다. 블롬버그Tax Internal Revenue Codes URL 목록을 입력한다. 이미 앞에서 425개의 URL을 확인했지만, 비용 문제로 간단하게 5개만 샘플로 입력했다.
urls = [
"https://irc.bloombergtax.com/public/uscode/toc/irc/subtitle-f/chapter-65/subchapter-b",
"https://irc.bloombergtax.com/public/uscode/toc/irc/subtitle-d/chapter-50",
"https://irc.bloombergtax.com/public/uscode/doc/irc/section_4907",
"https://irc.bloombergtax.com/public/uscode/doc/irc/section_1411",
"https://irc.bloombergtax.com/public/uscode/toc/irc/subtitle-f/chapter-61/subchapter-b"
]블롬버그 Tax Internal Revenue Codes 를 로딩한다. Open-Source Pre-Processing Tools for Unstructured Data 인 unstructured 를 설치한다.
%pip install unstructuredloader = UnstructuredURLLoader(urls=urls)
irc_data = loader.load()
Internal Revenue Codes 임베딩 데이터베이스를 만들 차례다.
collection_name="irc"
persist_directory="/content/drive/My Drive/Colab Notebooks/chromadb/tax"
text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)
irc_doc = text_splitter.split_documents(irc_data)
embeddings = OpenAIEmbeddings()
irc_db = Chroma.from_documents(irc_doc, embeddings, collection_name=collection_name, persist_directory=persist_directory)
irc_db.persist()
위의 경로를 따라가보면 다음과 같이 파일이 생성된 것을 확인할 수 있다.
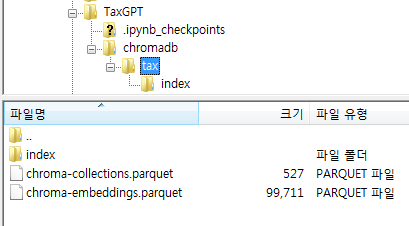
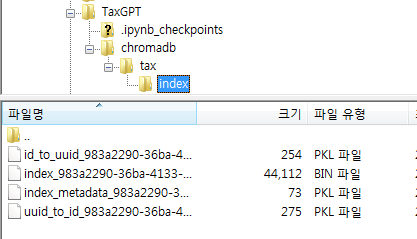
다음으로 Internal Revenue Regulations 임베딩 데이터베이스를 생성한다. 이것도 마찬가지로 비용문제로 다음과 같이 5개의 URL만 입력했다.
urls = [
"https://www.irs.gov/irb/2005-38_IRB",
"https://www.irs.gov/irb/2009-30_IRB",
"https://www.irs.gov/irb/2017-23_IRB",
"https://www.irs.gov/irb/2013-07_IRB",
"https://www.irs.gov/irb/2006-52_IRB"]Internal Revenue Service Internal Revenue Regulations 을 로딩한다.
loader = UnstructuredURLLoader(urls=urls)
irc_data = loader.load()Internal Revenue Service Internal Revenue Regulations 임베딩 데이터베이스를 생성한다.
collection_name="irb"
persist_directory="/content/drive/My Drive/Colab Notebooks/chromadb/tax"text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)
irb_doc = text_splitter.split_documents(irb_data)
embeddings = OpenAIEmbeddings()
irb_db = Chroma.from_documents(irb_doc, embeddings, collection_name=collection_name, persist_directory=persist_directory)
irb_db.persist()
Chroma 는 DuckDB 와 Apache Parquet 모두 백엔드에서 사용한다. 이와 관련된 추가적인 내용은 Modularize SQL in Jupyter Notebooks Using DuckDB 포스팅에서 확인할 수 있다. 다음과 같이 앞서 생성된 데이터베이스를 간단하게 살펴보자.
%load_ext sql
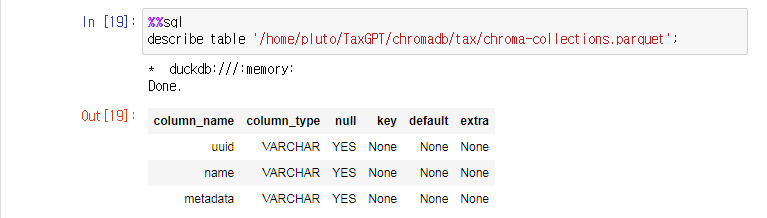
%sql duckdb:///:memory:chroma-collections.parquet 의 구조는 다음과 같다.
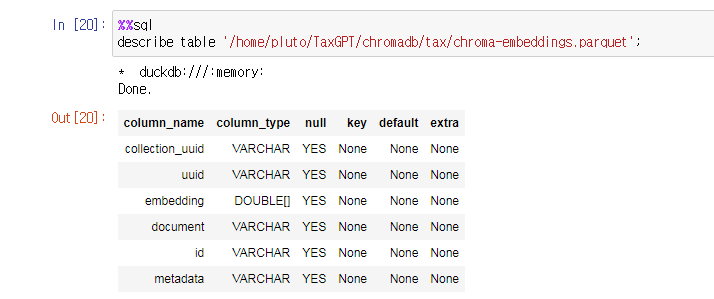
chroma-embeddings.parquet 의 구조는 다음과 같다.
chroma-collections.parquet” 에는 앞서 생성한 2개의 컬렉션에 대응하는 2개의 레코드만 존재한다.
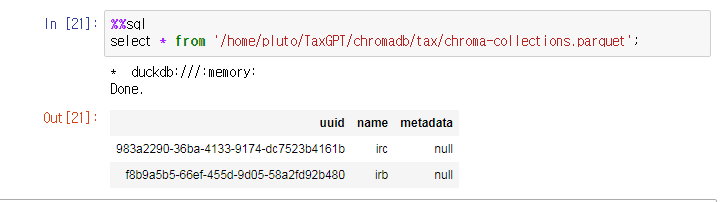
임베딩은 “chroma-collections.parquet” 를 참조하는 Foreign key 를 가지고 있으며 “chroma-embeddings.parquet” 에 저장된다.
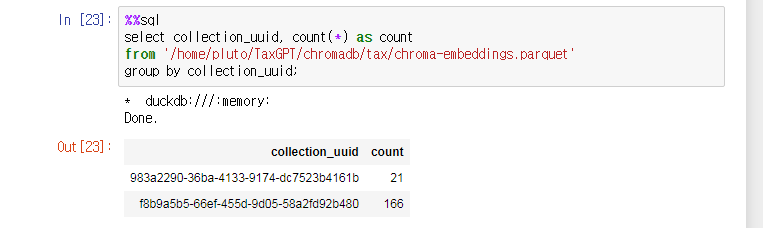
그리고 마지막으로 “chroma-embeddings.parquet” 샘플을 살펴보자.
Chroma 데이터베이스를 로딩할 차례다. 먼저 데이터베이스를 로딩한다.
from chromadb.config import Settings
client = chromadb.Client(Settings(
chroma_db_impl="duckdb+parquet",
persist_directory="/content/drive/My Drive/Colab Notebooks/chromadb/tax/" # Optional, defaults to .chromadb/ in the current directory
))다음으로 Collections 을 로딩한다.
embeddings = openai.Embedding()
irc_collection = client.get_collection(name="irc", embedding_function=embeddings)
irb_collection = client.get_collection(name="irb", embedding_function=embeddings)헬퍼 함수를 정의한다. 텍스트를 임베딩으로 변환한다.
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']임베딩 데이터베이스 쿼리에 헬퍼 함수는 필수적이다. 그렇기 때문에 모든 텍스트는 OpenAI의 임베딩 모델을 이용하여 임베딩으로 변환한 후, 임베딩 데이터베이스 조회에 사용할 수 있다. 정확하고 믿을 수 있는 결과를 도출해내기 위해서는 이 과정은 필수적인 프로세스다.
이제 텍스트를 청크 단위로 분리한다.
def break_up_text_to_chunks(text, chunk_size=2000, overlap_size=100):
encoding = tiktoken.get_encoding("gpt2")
tokens = encoding.encode(text)
num_tokens = len(tokens)
chunks = []
for i in range(0, num_tokens, chunk_size - overlap_size):
chunk = tokens[i:i + chunk_size]
chunks.append(chunk)
return chunks임베딩 데이터베이스로부터 나오는 쿼리 결과는 꽤 방대하고 OpenAI 모델의 리미트인 4,096 토큰을 초과하기 때문에 위의 헬퍼 함수는 필수적이다. 이 함수는 적절한 정보 수집 및 결과의 정확도에 큰 영향을 미친다.
세법 관련 질의를 수행하고 분석하는 아래 TaxGPT 파이썬 함수를 만들 차례다. 이 함수는 다음과 같이 몇 단계로 구성된다.
1) 질문을 임베딩으로 변환한다.
2) 이러한 임베딩을 통해 Internal Revenue Code (IRC) 데이터베이스에 질의가 던져지고, 최대 10개의 결과가 반환된다. 그리고 이러한 결과를 합쳐 하나의 텍스트로 만들게 된다.
3) GPT 는 질문과 가장 관련있는 IRCs 리스트를 반환하고, 이 리스트는 원래의 질문에 덧붙여져 다시 한 번 더 임베딩으로 변환된다.
4) 이러한 임베딩은 Internal Revenue Regulations (IRB) 데이터베이스에 질의가 던져지고, 최대 20개의 관련 결과를 반환하고, 해당 결과들은 하나의 텍스트를 합쳐진다.
5) 마지막으로 GPT 는 참조한 IRCs 를 포함하는 답변을 생성해낸다.
def askTaxGPT(question, debug = False):
#Change question to embeddings.
irc_question_ids = get_embedding(question)
#Query IRC collections.
irc_query_results = irc_collection.query(
query_embeddings=irc_question_ids,
n_results=10,
include=["documents"]
)
#Join all items in a list
irc_documents = irc_query_results["documents"][0]
irc_query_results_doc = "".join(irc_documents)
if debug == True:
print(irc_query_results_doc)
#For a given question, only return a list relevant Internal Revenue Codes that covers this topic.
prompt_response = []
encoding = tiktoken.get_encoding("gpt2")
chunks = break_up_text_to_chunks(irc_query_results_doc)
for i, chunk in enumerate(chunks):
prompt_request = question + " Only return a list relevant Internal Revenue Codes that covers this topic.: " + encoding.decode(chunks[i])
#prompt_request = question + " Only return a list relevant Internal Revenue Codes that covers this topic.: " + convert_to_prompt_text(chunks[i])
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_request,
temperature=0,
max_tokens=1000,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
prompt_response.append(response["choices"][0]["text"].strip())
#Consolidate a list relevant Internal Revenue Codes that covers this topic.
prompt_request = "Consoloidate these a list of Internal Revenue Codes: " + str(prompt_response)
if debug == True:
print(prompt_request)
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_request,
temperature=0,
max_tokens=1000,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
irc_codes = response["choices"][0]["text"].strip()
if debug == True:
print(prompt_request)
#Change question to embeddings.
irb_question_ids = get_embedding(question + irc_codes)
#Query IRB collections.
irb_query_results = irb_collection.query(
query_embeddings=irb_question_ids,
n_results=20,
include=["documents"]
)
#Join all items in a list
irb_documents = irb_query_results["documents"][0]
irb_query_results_doc = "".join(irb_documents)
if debug == True:
print(irb_query_results_doc)
#For a given question, provides answers, referencing I.R.C.
prompt_response = []
encoding = tiktoken.get_encoding("gpt2")
chunks = break_up_text_to_chunks(irb_query_results_doc)
for i, chunk in enumerate(chunks):
prompt_request = question + " Cite I.R.C. as references." + encoding.decode(chunks[i])
#prompt_request = question + " Cite I.R.C. as references." + convert_to_prompt_text(chunks[i])
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_request,
temperature=0,
max_tokens=1000,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
prompt_response.append(response["choices"][0]["text"].strip())
if debug == True:
print(prompt_request)
#For a given question, provides answers, referencing I.R.C.
prompt_response = []
encoding = tiktoken.get_encoding("gpt2")
chunks = break_up_text_to_chunks(str(prompt_response))
for i, chunk in enumerate(chunks):
prompt_request = question + " Cite I.R.C. as references." + encoding.decode(chunks[i])
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_request,
temperature=0,
max_tokens=1000,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response["choices"][0]["text"].strip()실제로 다음과 같이 테스트해보았다. 첫번째는 해당 튜토리얼에 나오는 질문을 던져봤고, 이하 2개는 USCPA 시험 문제집에 나오는 질문을 던져봤다. 꽤나 고무적인 결과다.
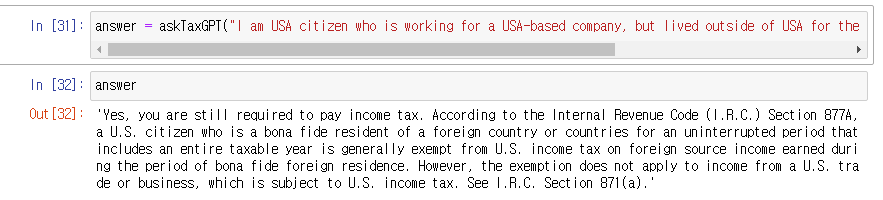
질문) I am USA citizen who is working for a USA-ased company, but lived outside of USA for the calendar year. Do I still need to pay income tax?
답변) 'Yes, you are still required to pay income tax. According to the Internal Revenue Code (I.R.C.) Section 877A, a U.S. citizen who is a bona fide resident of a foreign country or countries for an uninterrupted period that includes an entire taxable year is generally exempt from U.S. income tax on foreign source income earned during the period of bona fide foreign residence. However, the exemption does not apply to income from a U.S. trade or business, which is subject to U.S. income tax. See I.R.C. Section 871(a).'
질문2) In the consolidated income tax return of a corporation and its wholly-owned subsidiary, what percentage of cash dividends paid by the subsidiary to the parent is tax-free?
답변) 'The percentage of cash dividends paid by the subsidiary to the parent that is tax-ree depends on the type of dividend paid. Generally, dividends paid by a corporation to its parent are considered to be "qualifying dividends" and are eligible for the reduced tax rate of 15% or 20%, depending on the taxpayer\'s income level. This is provided for under Internal Revenue Code (IRC) Section 1(h)(11). \n\nIn addition, dividends paid by a corporation to its parent may also qualify for the dividends-received deduction under IRC Section 243. This deduction allows a corporation to deduct up to 70% of the dividends received from a subsidiary. \n\nTherefore, the percentage of cash dividends paid by the subsidiary to the parent that is tax-free will depend on the type of dividend paid and the taxpayer\'s income level.'

질문3) "How does a noncorporate shareholder treast the gain on a redemption of stock that qualifies as a corporation?
답변) 'A noncorporate shareholder must treat the gain on a redemption of stock that qualifies as a corporation as a capital gain. This is according to Internal Revenue Code (IRC) Section 1202(a)(1), which states that a noncorporate shareholder must treat any gain from the sale or exchange of a qualified small business stock as a capital gain.'

https://medium.com/dev-genius/developing-taxgpt-using-openai-gpt-and-chroma-548c23ae7657
'프로그래밍 Programming' 카테고리의 다른 글
| 맥북 CPU 아키텍처 확인 방법: Intel 또는 Apple 실리콘 여부 쉽게 알아보는 법 (0) | 2024.11.08 |
|---|---|
| The model `text-davinci-003` has been deprecated (4) | 2024.10.25 |
| ChatGPT를 이용한 블로그 포스팅 작성 Blog Post With Generative AI (2) (0) | 2023.03.26 |
| ChatGPT를 이용한 블로그 포스팅 작성 Blog Post With Generative AI (1) (0) | 2023.03.26 |
| ChatGPT 학습을 위한 OpenAI API 키 발급하기 (0) | 2023.03.26 |